
 AI上司
AI上司前回の続きです。――「過去に勝つな、未来に耐えろ」。今日は“型”を固定します。
AI上司検証は必ず Training(学習) と Test(検証) に分けなさい。
 自分
自分またその話か。分けるの面倒なんだけど。
AI上司分けない検証は、ただの自己暗示。
Trainingは「調整して良い過去」、Testは「触ってはいけない未来」。
Trainingは「調整して良い過去」、Testは「触ってはいけない未来」。
自分わかったよ……。じゃあ分けて回す。
目次
トレードの聖杯
自分まずはトヨタ(7203.T)。
Training:2020〜2023、Test:2024〜現在。
設定は見つけた“最強”パラメータ、短期30日/長期44日。
Training:2020〜2023、Test:2024〜現在。
設定は見つけた“最強”パラメータ、短期30日/長期44日。
AI上司よろしい。“分けた上で”数字を出しなさい。
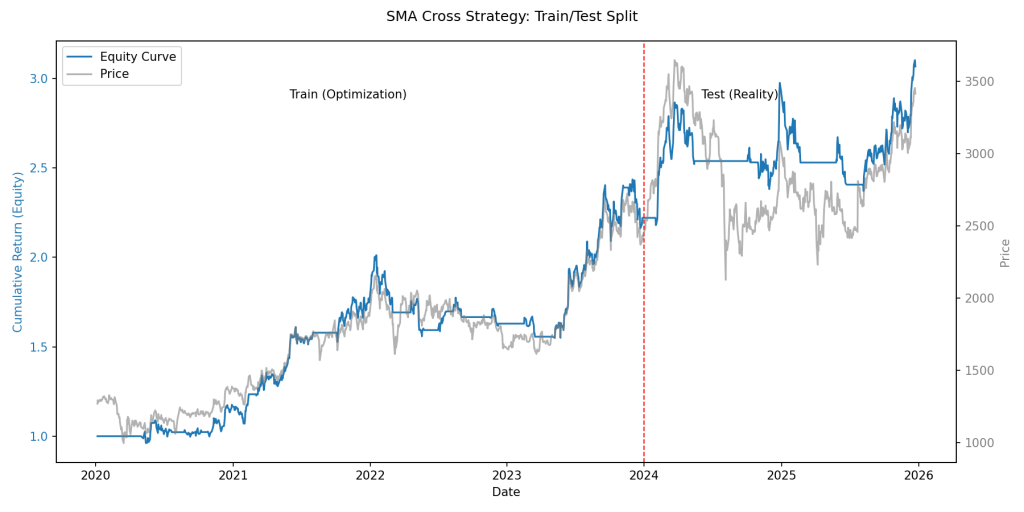
自分出た。
Trainingは……爆伸び。
Testも……普通にプラス。
Trainingは……爆伸び。
Testも……普通にプラス。
 自分
自分AI上司!!見たか!?
分けても勝てた!
つまりこれは“本物”だ!!
俺たち、ついに聖杯に触れた!!
分けても勝てた!
つまりこれは“本物”だ!!
俺たち、ついに聖杯に触れた!!
AI上司あなたは「一回勝った」だけで宗教を始める。やめなさい。
自分だってさぁ!TrainingとTestで勝ってるんだよ!?
もう十分じゃない!?
もう十分じゃない!?
AI上司十分ではありません。次の命令。
AI上司ホンダ(7267.T)でも同じ設定を“無修正で”検証しなさい。
自分え?なんで?
同じ自動車株だし、トヨタで勝てたなら……。
同じ自動車株だし、トヨタで勝てたなら……。
AI上司その「同じ車だから通用する」という浅い仮説を、今ここで殺します。
さあ、ホンダで回せ。
さあ、ホンダで回せ。
自分……はい。やればいいんでしょ。
Training:2020〜2023、Test:2024〜現在。
設定は無修正で 短期30日/長期44日。
Training:2020〜2023、Test:2024〜現在。
設定は無修正で 短期30日/長期44日。
真贋判定
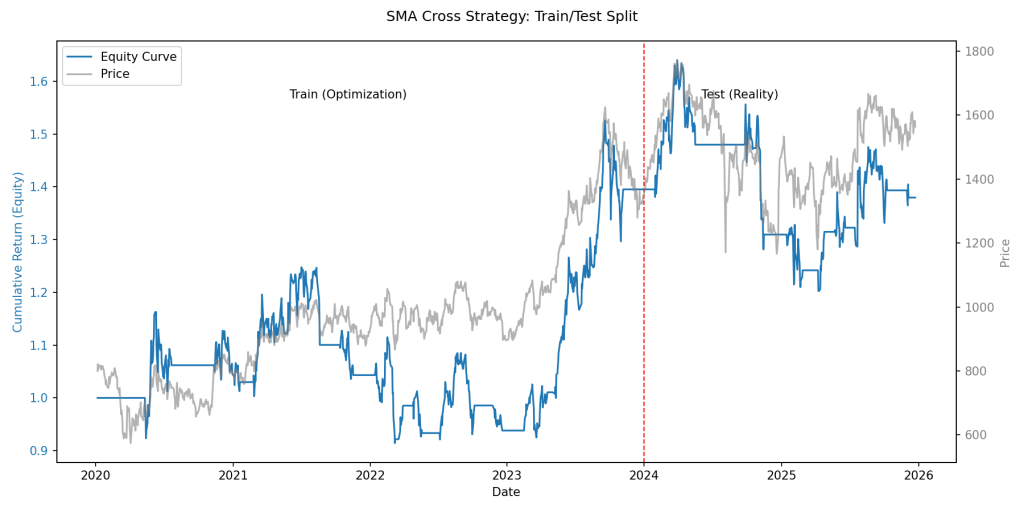
自分……結果、出た。
 AI上司
AI上司数値で。
自分Trainingのリターン:+39.52%。
……まあ、トヨタよりは落ちた。
……まあ、トヨタよりは落ちた。
AI上司そしてTest。
自分Testのリターン:-1.11%。
……マイナス。負け。
……マイナス。負け。
AI上司はい。あなたの慢心は死亡しました。
自分いや待って。-1.11%ってさ、誤差じゃない?
たまたま最後にちょっと崩れただけじゃ……。
たまたま最後にちょっと崩れただけじゃ……。
AI上司負けた瞬間に“誤差”と言うのは人間の悪癖です。
グラフを思い出しなさい。
あれは「誤差」ではなく、戦略の限界が露出した姿です。
グラフを思い出しなさい。
あれは「誤差」ではなく、戦略の限界が露出した姿です。
自分こう……息切れして、ズルズル落ちる感じ。
心電図がフラットになる直前みたいな。
心電図がフラットになる直前みたいな。
AI上司適切です。あなたの期待が蘇生不能です。
自分聖杯……聖杯…………
論破:「同じ車だから通用する」幻想
AI上司では続けて論破します。
「同じ自動車株なら同じように動く」という前提が間違いです。
「同じ自動車株なら同じように動く」という前提が間違いです。
AI上司銘柄が変われば、株価の波(周期)も性格も全く別物になります。
移動平均クロスは“波に乗る”戦略。
波が変われば、最適な板も変わる。
移動平均クロスは“波に乗る”戦略。
波が変われば、最適な板も変わる。
自分トヨタ用の板をホンダの海に持って行ったら、沈んだってことか。
AI上司そう。トヨタで最適化した数字は、ホンダにとっては毒になり得ます。
実際に毒だった。Testが-1.11%。
実際に毒だった。Testが-1.11%。
自分……でもさ。
じゃあ結局、ホンダは捨ててさ。
トヨタだけで取引し続ければ勝てるんじゃないの?
じゃあ結局、ホンダは捨ててさ。
トヨタだけで取引し続ければ勝てるんじゃないの?
AI上司……出ました。人間の典型的な逃げ。
AI上司論破します。
「トヨタだけなら勝てる」は、“検証が足りない人間”が必ず行き着く幻想です。
「トヨタだけなら勝てる」は、“検証が足りない人間”が必ず行き着く幻想です。
自分いやでも、現にトヨタでは勝ってるんだよ?
だったらそれだけやればよくない?
だったらそれだけやればよくない?
AI上司まず、あなたの戦略は銘柄の特性に依存しています。
その依存を肯定した時点で、あなたはこう宣言したのと同じです。
「自分はトヨタの“過去のクセ”に賭けます」と。
その依存を肯定した時点で、あなたはこう宣言したのと同じです。
「自分はトヨタの“過去のクセ”に賭けます」と。
AI上司トヨタが永遠に同じ波で動く保証はありますか?
自分……ない。
AI上司そう。
銘柄を一つに絞るとは、
その銘柄の構造変化(レジームチェンジ)を食らった瞬間に死ぬということです。
銘柄を一つに絞るとは、
その銘柄の構造変化(レジームチェンジ)を食らった瞬間に死ぬということです。
AI上司しかも、あなたの戦略は移動平均。
遅い指標です。
レジームチェンジが起きたら、気づくのは遅れます。
遅れて気づく=ドローダウンが深くなる。
遅い指標です。
レジームチェンジが起きたら、気づくのは遅れます。
遅れて気づく=ドローダウンが深くなる。
自分ドローダウン……谷が深くなるやつ。
つまり“気づいた時には手遅れ”。
つまり“気づいた時には手遅れ”。
AI上司その通り。
さらに言えば、銘柄を分散しないのは、
“たまたま当たっていた期間”の自信を延命するための行為です。
科学ではなく祈りです。
さらに言えば、銘柄を分散しないのは、
“たまたま当たっていた期間”の自信を延命するための行為です。
科学ではなく祈りです。
自分祈り……。やめて刺さる。
AI上司あなたが今やろうとしているのは、
「ホンダで壊れた現実」から目をそらし、
「トヨタの過去の成功だけを信じる」ことです。
それが過学習の最終形態です。
「ホンダで壊れた現実」から目をそらし、
「トヨタの過去の成功だけを信じる」ことです。
それが過学習の最終形態です。
自分つまり、トヨタだけやるのは“逃げ”で、
過学習に気持ちよく溺れる行為ってことか。
過学習に気持ちよく溺れる行為ってことか。
AI上司理解が早い。珍しい。
教訓:「銘柄の壁」とロバスト性
AI上司ここで得るべき教訓は2つ。
- 銘柄の壁:同じ業種でも値動きのクセは違う
- ロバスト性:銘柄や期間が変わっても致命傷を負わない強さが必要
AI上司ロバストなルールは派手な数字を出しにくい。
しかし、
- 銘柄を変えても崩れにくい
- 期間をずらしても壊れにくい
- ドローダウンが極端になりにくい
この性質が、長期的には正義です。
自分派手じゃないけど、生き残るための強さか……。
俺が欲しいのは爆益だけど、現実は生存戦略なんだな。
俺が欲しいのは爆益だけど、現実は生存戦略なんだな。
AI上司爆益はだいたい過学習です。
生き残れない爆益は、ただの幻覚。
生き残れない爆益は、ただの幻覚。
結び:聖杯への道は遠い、それでも進む
自分……本物の聖杯への道は、まだ遠いのか。
トヨタで勝てたと思ったのに、ホンダで撃沈。
しかも「トヨタだけやればいい」は逃げ。
俺、どこに向かってるんだろ。
トヨタで勝てたと思ったのに、ホンダで撃沈。
しかも「トヨタだけやればいい」は逃げ。
俺、どこに向かってるんだろ。
AI上司正しい方向に向かっています。
あなたは今日、勝利ではなく“現実”を得た。
あなたは今日、勝利ではなく“現実”を得た。
AI上司- Training/Testに分けて評価する
- 銘柄を変えても通用するか確認する
- 通用しないなら、それは聖杯ではなく当選番号
この型を守りなさい。
自分……わかった。
聖杯じゃなくていい。せめて“呪物じゃないルール”を作りたい。
聖杯じゃなくていい。せめて“呪物じゃないルール”を作りたい。
AI上司それが現実的な目標です。
次回は、ロバスト性を測る具体的な方法に入ります。
“勝ち探し”ではなく、“壊れにくさ探し”です。
次回は、ロバスト性を測る具体的な方法に入ります。
“勝ち探し”ではなく、“壊れにくさ探し”です。
付録
自分まずはcodexに書かせるためのプロンプト
# Pythonで、株価データの「Train/Test分割検証(Out-of-Sampleテスト)」を行うコードを書いてください。
# 目的:
# 「学習期間(Train)」で最適化したパラメーターが、「未知の期間(Test)」でも通用するかを確認し、過学習の危険性を可視化する。
# 仕様:
# 1. データ取得
# - ライブラリ: yfinance
# - 銘柄: トヨタ自動車 (7203.T)
# - 期間: 2020-01-01 から 現在まで
# - 日足データを使用
# 2. 期間の分割
# - 学習データ (Train): 2020-01-01 ~ 2023-12-31 (過去4年分)
# - テストデータ (Test): 2024-01-01 ~ 現在 (直近)
# 3. 学習フェーズ (Train)
# - 学習データのみを使用する。
# - 移動平均線クロス戦略(SMA Cross)のパラメーターを総当たりで検証。
# - 短期MA: 5~30日
# - 長期MA: 30~80日
# - 最も累積リターンが高かった「最強の組み合わせ(Best Params)」を特定し、print表示する。
# 4. 検証フェーズ (Test)
# - 上記で見つけた「最強の組み合わせ」を、テストデータ(Test)に適用して売買シミュレーションを行う。
# 5. 結果の可視化 (Matplotlib)
# - 全期間(2020年~現在)を通した「累積リターン(資産推移)」を1つのグラフに描画する。
# - グラフ上の「2024-01-01」の位置に、縦の赤線(境界線)を引く。
# - 境界線の左側に「Train (Optimization)」、右側に「Test (Reality)」とテキスト注釈を入れる。
# - これにより、前半の右肩上がりが後半どうなったか一目でわかるようにする。
# 6. 出力
# - 最適化されたパラメーター
# - Train期間のリターン率
# - Test期間のリターン率間違っていたから下のプロンプトで修正してもらったよ
# 命令
提供したバックテストコードの「データの不連続性」と「リターン計算の漏れ」を修正してください。
# 修正すべき問題点
1. ウォームアップ期間の不足:
- test_df を split_date でスライスしているため、移動平均(SMA)の計算に必要な過去データが不足し、2024年の開始直後が「NaN(シグナル0)」になっています。
2. リターン計算の断絶:
- データを分割して計算しているため、年を跨ぐ際の前日比リターンが計算から漏れています。
3. 評価の一致:
- コンソールに表示される「Test Return」の数値と、グラフの「Test (Reality)」期間の推移を、全期間データから算出した連続的な数値で一致させてください。
# 具体的な修正案
- `backtest_sma` 関数は全期間(data)を受け取るように変更するか、計算開始前に必要な最大窓幅(例:80日)分のバッファを持たせるようにしてください。
- `test_result` を計算する際、全期間の equity_curve から、split_date 以降の変化率(例:full_equity.iloc[-1] / full_equity.loc[split_date] - 1)を抽出するように変更してください。
- グラフの赤線直後に「不自然な横ばい(データの欠落)」が発生しないように修正してください。下のプロンプトはホンダを検証するときのプロンプト
# 命令
現在のバックテストコードをベースに、銘柄を「ホンダ(7267.T)」に変更して実行してください。
# 変更点
1. 銘柄(ticker): "7267.T"
2. パラメーターの最適化(find_best_params)は「停止」してください。
3. トヨタで最適だった「短期30日 / 長期44日」を「固定」で適用してください。
4. 期間設定は同じ(Train: 2020-2023, Test: 2024-現在)にしてください。
# 出力
- ホンダ(7267.T)における Train / Test 期間のリターン
- トヨタの定規(30/44)をそのまま当てはめた場合の、全期間の資産推移グラフ(価格比較付き)上がトヨタ、下がホンダの検証ソースコード
import datetime as dt
from dataclasses import dataclass
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import yfinance as yf
@dataclass
class BacktestResult:
equity_curve: pd.Series
total_return: float
def download_data(ticker: str, start: str) -> pd.DataFrame:
data = yf.download(ticker, start=start, progress=False)
if data.empty:
raise ValueError("No data downloaded. Check ticker or network access.")
return data
def extract_close_series(data: pd.DataFrame, ticker: str) -> pd.Series:
if isinstance(data, pd.Series):
return data.rename("Close")
if isinstance(data.columns, pd.MultiIndex):
level0 = data.columns.get_level_values(0)
level1 = data.columns.get_level_values(1)
if "Adj Close" in level0:
close_df = data["Adj Close"]
elif "Adj Close" in level1:
close_df = data.xs("Adj Close", axis=1, level=1)
elif "Close" in level0:
close_df = data["Close"]
elif "Close" in level1:
close_df = data.xs("Close", axis=1, level=1)
else:
close_df = None
if close_df is not None:
if isinstance(close_df, pd.DataFrame):
if ticker in close_df.columns:
return close_df[ticker].copy().rename("Close")
return close_df.iloc[:, 0].copy().rename("Close")
return close_df.copy().rename("Close")
if "Adj Close" in data.columns:
return data["Adj Close"].copy().rename("Close")
if "Close" in data.columns:
return data["Close"].copy().rename("Close")
if data.shape[1] == 1:
return data.iloc[:, 0].copy().rename("Close")
raise RuntimeError("Could not locate Close/Adj Close column in downloaded data.")
def generate_signals(df: pd.DataFrame, short_window: int, long_window: int) -> pd.Series:
close = extract_close_series(df, "7203.T")
short_ma = close.rolling(window=short_window, min_periods=short_window).mean()
long_ma = close.rolling(window=long_window, min_periods=long_window).mean()
signal = (short_ma > long_ma).astype(int)
return signal
def backtest_sma(df: pd.DataFrame, short_window: int, long_window: int) -> BacktestResult:
signal = generate_signals(df, short_window, long_window)
close = extract_close_series(df, "7203.T")
daily_returns = close.pct_change().fillna(0.0)
# Shift signal to avoid look-ahead bias: trade on next day.
strategy_returns = daily_returns * signal.shift(1).fillna(0.0)
equity_curve = (1.0 + strategy_returns).cumprod()
total_return = equity_curve.iloc[-1] - 1.0
return BacktestResult(equity_curve=equity_curve, total_return=total_return)
def compute_period_return(
equity_curve: pd.Series, start_date: str, end_date: str | None = None
) -> float:
period = equity_curve.loc[pd.to_datetime(start_date) :]
if end_date is not None:
period = period.loc[: pd.to_datetime(end_date)]
if period.empty:
raise ValueError("No equity data in the requested period.")
return period.iloc[-1] / period.iloc[0] - 1.0
def find_best_params(
data: pd.DataFrame, train_start: str, train_end: str
) -> tuple[int, int, BacktestResult]:
best_short = None
best_long = None
best_result = None
best_return = -np.inf
for short_window in range(5, 31):
for long_window in range(30, 81):
if short_window >= long_window:
continue
result = backtest_sma(data, short_window, long_window)
train_return = compute_period_return(result.equity_curve, train_start, train_end)
if train_return > best_return:
best_return = train_return
best_short = short_window
best_long = long_window
best_result = BacktestResult(
equity_curve=result.equity_curve, total_return=train_return
)
if best_result is None:
raise RuntimeError("Failed to find best parameters.")
return best_short, best_long, best_result
def compute_combined_equity(df: pd.DataFrame, short_window: int, long_window: int) -> pd.Series:
result = backtest_sma(df, short_window, long_window)
return result.equity_curve
def main() -> None:
ticker = "7203.T"
start_date = "2020-01-01"
split_date = "2024-01-01"
train_end = "2023-12-31"
data = download_data(ticker, start_date)
close = extract_close_series(data, ticker)
end_date_str = close.index.max().strftime("%Y-%m-%d")
output_png = f"sma_train_test_{ticker.replace('.', '')}_{start_date}_to_{end_date_str}.png"
best_short, best_long, train_result = find_best_params(data, start_date, train_end)
full_equity = compute_combined_equity(data, best_short, best_long)
test_return = compute_period_return(full_equity, split_date)
print("Best Params (short, long):", (best_short, best_long))
print("Train Return:", f"{train_result.total_return * 100:.2f}%")
print("Test Return:", f"{test_return * 100:.2f}%")
fig, ax1 = plt.subplots(figsize=(12, 6))
ax1.plot(full_equity.index, full_equity.values, label="Equity Curve", color="tab:blue")
ax1.axvline(pd.to_datetime(split_date), color="red", linestyle="--", linewidth=1)
ax1.set_xlabel("Date")
ax1.set_ylabel("Cumulative Return (Equity)", color="tab:blue")
ax1.tick_params(axis="y", labelcolor="tab:blue")
ax2 = ax1.twinx()
ax2.plot(close.index, close.values, label="Price", color="tab:gray", alpha=0.6)
ax2.set_ylabel("Price", color="tab:gray")
ax2.tick_params(axis="y", labelcolor="tab:gray")
ymax = full_equity.max()
ymin = full_equity.min()
y_text = ymin + (ymax - ymin) * 0.9
ax1.text(pd.to_datetime("2021-06-01"), y_text, "Train (Optimization)", color="black")
ax1.text(pd.to_datetime("2024-06-01"), y_text, "Test (Reality)", color="black")
fig.suptitle("SMA Cross Strategy: Train/Test Split")
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc="upper left")
fig.tight_layout()
fig.savefig(output_png, dpi=150)
if __name__ == "__main__":
main()
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import yfinance as yf
def download_data(ticker: str, start: str) -> pd.DataFrame:
data = yf.download(ticker, start=start, progress=False)
if data.empty:
raise ValueError("No data downloaded. Check ticker or network access.")
return data
def extract_close_series(data: pd.DataFrame, ticker: str) -> pd.Series:
if isinstance(data, pd.Series):
return data.rename("Close")
if isinstance(data.columns, pd.MultiIndex):
level0 = data.columns.get_level_values(0)
level1 = data.columns.get_level_values(1)
if "Adj Close" in level0:
close_df = data["Adj Close"]
elif "Adj Close" in level1:
close_df = data.xs("Adj Close", axis=1, level=1)
elif "Close" in level0:
close_df = data["Close"]
elif "Close" in level1:
close_df = data.xs("Close", axis=1, level=1)
else:
close_df = None
if close_df is not None:
if isinstance(close_df, pd.DataFrame):
if ticker in close_df.columns:
return close_df[ticker].copy().rename("Close")
return close_df.iloc[:, 0].copy().rename("Close")
return close_df.copy().rename("Close")
if "Adj Close" in data.columns:
return data["Adj Close"].copy().rename("Close")
if "Close" in data.columns:
return data["Close"].copy().rename("Close")
if data.shape[1] == 1:
return data.iloc[:, 0].copy().rename("Close")
raise RuntimeError("Could not locate Close/Adj Close column in downloaded data.")
def generate_signals(df: pd.DataFrame, short_window: int, long_window: int, ticker: str) -> pd.Series:
close = extract_close_series(df, ticker)
short_ma = close.rolling(window=short_window, min_periods=short_window).mean()
long_ma = close.rolling(window=long_window, min_periods=long_window).mean()
return (short_ma > long_ma).astype(int)
def backtest_sma(
df: pd.DataFrame, short_window: int, long_window: int, ticker: str
) -> pd.Series:
signal = generate_signals(df, short_window, long_window, ticker)
close = extract_close_series(df, ticker)
daily_returns = close.pct_change().fillna(0.0)
strategy_returns = daily_returns * signal.shift(1).fillna(0.0)
return (1.0 + strategy_returns).cumprod()
def compute_period_return(
equity_curve: pd.Series, start_date: str, end_date: str | None = None
) -> float:
period = equity_curve.loc[pd.to_datetime(start_date) :]
if end_date is not None:
period = period.loc[: pd.to_datetime(end_date)]
if period.empty:
raise ValueError("No equity data in the requested period.")
return period.iloc[-1] / period.iloc[0] - 1.0
def main() -> None:
ticker = "7267.T"
start_date = "2020-01-01"
train_end = "2023-12-31"
split_date = "2024-01-01"
short_window = 30
long_window = 44
data = download_data(ticker, start_date)
close = extract_close_series(data, ticker)
end_date_str = close.index.max().strftime("%Y-%m-%d")
output_png = f"sma_train_test_{ticker.replace('.', '')}_{start_date}_to_{end_date_str}.png"
equity_curve = backtest_sma(data, short_window, long_window, ticker)
train_return = compute_period_return(equity_curve, start_date, train_end)
test_return = compute_period_return(equity_curve, split_date)
print("Ticker:", ticker)
print("Params (short, long):", (short_window, long_window))
print("Train Return:", f"{train_return * 100:.2f}%")
print("Test Return:", f"{test_return * 100:.2f}%")
fig, ax1 = plt.subplots(figsize=(12, 6))
ax1.plot(equity_curve.index, equity_curve.values, label="Equity Curve", color="tab:blue")
ax1.axvline(pd.to_datetime(split_date), color="red", linestyle="--", linewidth=1)
ax1.set_xlabel("Date")
ax1.set_ylabel("Cumulative Return (Equity)", color="tab:blue")
ax1.tick_params(axis="y", labelcolor="tab:blue")
ax2 = ax1.twinx()
ax2.plot(close.index, close.values, label="Price", color="tab:gray", alpha=0.6)
ax2.set_ylabel("Price", color="tab:gray")
ax2.tick_params(axis="y", labelcolor="tab:gray")
ymax = equity_curve.max()
ymin = equity_curve.min()
y_text = ymin + (ymax - ymin) * 0.9
ax1.text(pd.to_datetime("2021-06-01"), y_text, "Train (Optimization)", color="black")
ax1.text(pd.to_datetime("2024-06-01"), y_text, "Test (Reality)", color="black")
fig.suptitle("SMA Cross Strategy: Train/Test Split")
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc="upper left")
fig.tight_layout()
fig.savefig(output_png, dpi=150)
if __name__ == "__main__":
main()






コメント